FlexFlow Serve: Low-Latency, High-Performance LLM Serving
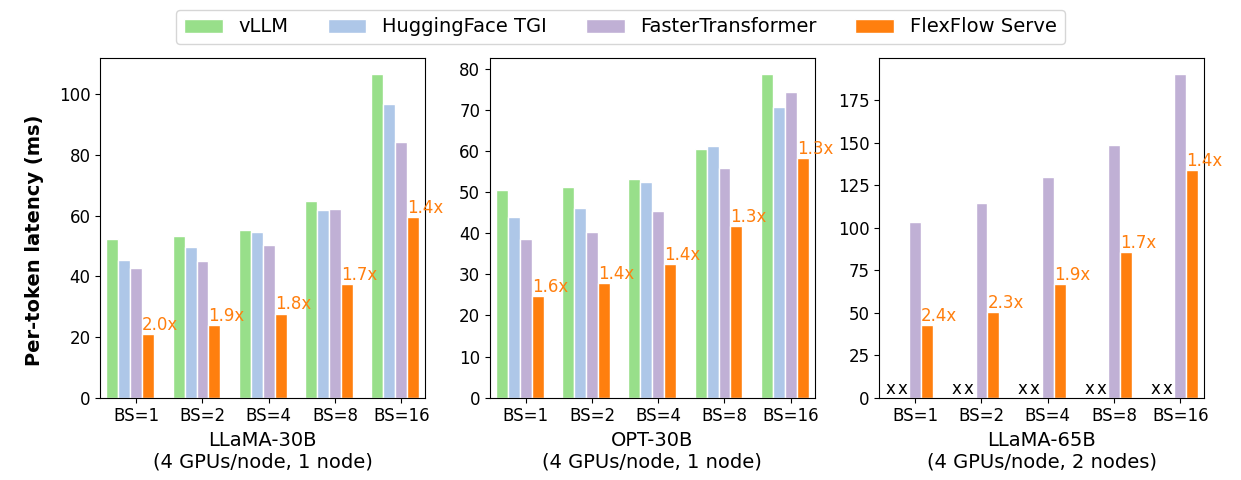
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. FlexFlow Serve is an open-source compiler and distributed system for low latency, high performance LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.